C16x Microcontroller FAQ
This is the C16x Microcontroller FAQ - Frequently Asked Questions
around the C16x family (including C167, C165, C164, C163 and C161) by Infineon
Technologies (formerly Siemens Microelectronics) and ST10 family by STMicroelectronics are
answered with this document.
This FAQ was started by Olaf
'Olu' Pfeiffer and is now maintained by the Embedded Systems Academy: www.ESAcademy.com.
The original of this FAQ is kept in HTML, an ASCII version will no
longer be maded available.
Feel free to send your comments or corrections, error reports or
other contributions to FAQ@ESAcademy.com.
Last updated: 22nd of September, 2000
Contents
This FAQ is available in HTML. The "home" is at:
- /faq/c16x
(Server located in California, USA)
WARNING: Older versions of this FAQ are widely spread on the
internet. This is the "real" one with most up-to-date information.
This FAQ was put together by Olaf
'Olu' Pfeiffer. It is now maintained by the tutors of the Embedded Systems Academy: www.ESAcademy.com.
Special thanks to:
Michael Beach (Hitex UK) - Some of the technical parts are
based on his guide "An Introduction To The C16x Family". It is available in
HTML:
Robert Teufel, Axel Wolf, Harald Lehmann and many others at
Infineon
Thanks for the support! This FAQ benefits from all your inputs.
That's easy. Just send your material to FAQ@ESAcademy.com. Please be advised that material sent
in might be edited, before it is entered into this FAQ.
Since the conversion to HTML, this FAQ is not posted regulary to
newsgroups anymore. However, newsgroups discussing microcontroller issues are:
Only if you leave the FAQ as it is! If you take the HTML version,
make sure you do not forget any file. Do NOT edit, add or delete any part of the FAQ.
There are some, but not too many are updated on a regular basis. For
a start, check out:
The C16x is a 16-Bit microcontroller originally developed by Siemens
(today Infineon). Second source availablity for some devices by STMicroelectronics. Today,
STMicroelectronics offers also devices of their own aimed at specific applications.
Some performance indicators (as claimed by Siemens):
- 90% of instructions execute in 100ns at 20 MHz clock
- 100ns context switching enhances task processing
- Interrupt response 250ns min, 400ns typ. (50ns sample rate with
C176/C165)
- 500ns multiply, 1us divide
- 10 channel 10-bit A/D converter, 9.7us sample time
- Interrupts serviced by cycle stealing DMA (PEC)
- 1024 point FFT calculated in 28ms
- (Symmetrical, burst and single shot modes PWM)
The C16x is a RISC CMOS 16-Bit microcontroller. The key features are
(some only on specific derivatives):
- 16 bit CPU with 4 stage pipeline and jump cache
- 32 bit bus to internal ROM
- Flash versions up to 128K available
- up to 4K bytes internal dual port RAM
- 90% of instructions execute in 100ns (at 20 MHz clock)
- Register based architecture with multiple variable banks
- 100ns (at 20 MHz clock) context switching enhances task processing
- 8/16 bit external, mux/demux bus modes with HOLD/A
- 2 to 5 simultaneous bus modes (each with a chip select)
- Interrupt response 250ns min, 400ns typ. (50ns sample rate with
C176/C165)
- Interrupt with 16 priority levels in each of 4 groups
- Interrupts serviced by cycle stealing DMA (PEC)
- 4 to 16 channel 10-bit A/D with 9.7us sample time (at 20 MHz clock)
- 500ns multiply, 1us divide (at 20 MHz clock)
- Watchdog - 16 bit programmable
- 16 or 32 capture/compare channels
- based on two or four 16-bit time bases
- 4 channel PWM at 78KHz 8-bit resolution
- Boolean arithmetic and bit processing
- 5 general purpose 16-bit timer/counters
- von Neumann address space, up tp 16Mbytes
- 2 USART (SCC); 625KBaud async (5MBaud sync)
- up to 112 I/O lines
- QFP packages with 80, 100 or 144 pins
Available Peripherals:
- up to 2 asynchronous serial interfaces, USART (up to 625KBaud)
- up tp one synchronours serial interface (up to 5MBaud)
- up to 2 CAN 2.0B interfaces (Controller Area Network) with 16 message
objects
- up to one J1850 interface
- up to one I square C interface (I2C)
Traditional microcontrollers have one or more special registers
which can be used for mathematical, logical or Boolean operations. In the 8051, there is a
single "accumulator" with 8 other registers which may be used for handling local
variables or intermediate results in complex calculations. These additional registers are
also used to access memory locations via indirect and/or indexed addressing.
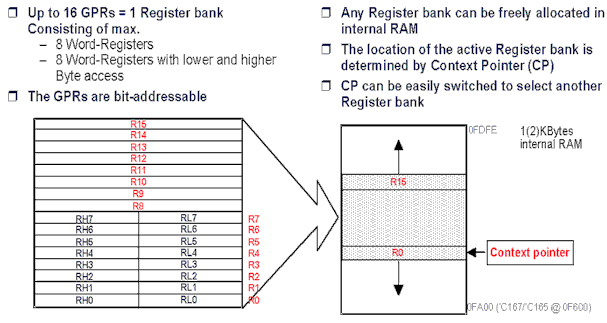 Conventional CPUs spend much time moving data from slow
memory areas into active registers. The RISC offers a very large number of general purpose
registers which may be used for local variables, parameters and intermediates. The C16x
provides sixteen 16-bit general purpose registers (GPRs), each of which may function as an
accumulator, indirect pointer or index. With such a large number of GPR's available, it
becomes realistic to keep all local and intermediate variables within the CPU throughout
quite large procedures. This limits external memory accesses and can yield a great
increase in speed.
Conventional CPUs spend much time moving data from slow
memory areas into active registers. The RISC offers a very large number of general purpose
registers which may be used for local variables, parameters and intermediates. The C16x
provides sixteen 16-bit general purpose registers (GPRs), each of which may function as an
accumulator, indirect pointer or index. With such a large number of GPR's available, it
becomes realistic to keep all local and intermediate variables within the CPU throughout
quite large procedures. This limits external memory accesses and can yield a great
increase in speed.
Further significant benefits are derived from the RISC technique of
register windowing. As stated above, up to 16 registers are available for use by the
program. However, by making the active register bank movable within a larger on-chip RAM,
the job of real time multi-tasking is considerably eased.
Central to this is the concept of a "Context Pointer"
(CP), which defines the current absolute base address of the active bank. Thus a reference
to "R0" means the register at the address indicated by the CP. The 16 registers
are then addressed with a 4-bit offset to the CP.
A good example of how the CP is used is with a background task and a
real-time interrupt existing at the same time. When the interrupt occurs, rather than
pushing all GPR's onto the stack, the CP of the current register bank is stacked and
simply switched to a new value, determined at link time, to yield a fresh register bank.
This results in a complete context switch in just one machine cycle but does rule out the
use of recursion. A hybrid method, which permits re-entrancy, uses the stack pointer to
calculate the new CP dynamically. Here, on entering the interrupt, the number of registers
now required is subtracted from the current SP and the result placed in CP, with the old
CP stacked. Thus the new register bank is located at the top of the old stack, with the
old CP and then the new stack following on immediately afterwards. On exiting the
interrupt routine, the original register bank is restored by POPping the old CP from the
stack. The SP is reinstated by adding the size of the new register bank onto the current
SP.
A further RISC refinement is register window overlapping which is
when a new procedure is called, part of the new register bank defined by CP' is coincident
with the original at CP:
R3' ; Register for subroutine's locals and intermediates
R2' ; Register for subroutine's locals and intermediates
R7 R1' ; Common register, R7 == R1'
CP' R6 R0' ; Common register, R6 == R0'
R5 ; Register for caller's locals and intermediates
R4 ; Register for caller's locals and intermediates
R3 ; Register for caller's locals and intermediates
R2 ; Register for caller's locals and intermediates
R1 ; Register for caller's locals and intermediates
CP R0 ; Register for caller's locals and intermediates
;============================================================
MODULE 1
; *** Assignment Of GPRs To Local Variables - Caller ***
x_var LIT 'R0' ; Local variable
y_var LIT 'R1' ; Local variable
parm1 LIT 'R6' ; Passed parameter 1
parm2 LIT 'R7' ; Passed parameter 2
result LIT 'R6' ; Value returned from sub routine
;============================================================
MODULE 2
; *** Assignment Of GPRs To Local Variables - Sub Routine ***
a_var LIT 'R2' ; Local variable
b_var LIT 'R3' ; Local variable
input1 LIT 'R0' ; Received parameter 1
input2 LIT 'R1' ; Received parameter 2
ret1 LIT 'R0' ; Final result returned in R0
By using some forethought, the programmer should arrange for any
value to be passed to the subroutine to be located in the common area so that all the
normal loading and unloading of parameters is avoided. This technique can be used in
either absolute or SP-relative register bank modes.
To get the best from a RISC's registers, the location of data needs
careful consideration: although highly orthogonal, the limited number of addressing modes
provided for MUL and DIV for example, can appear somewhat restrictive. Fortunately though,
most operands involved will already be in registers, so eliminating the need for many
addressing techniques.
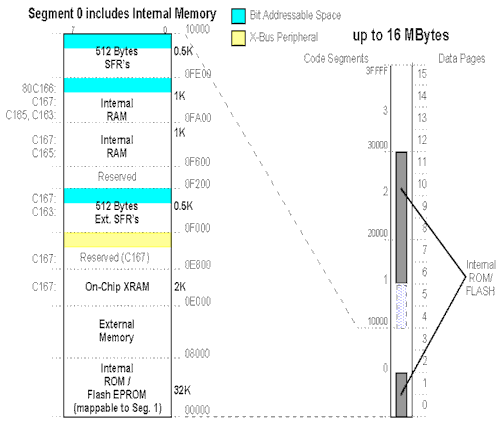 The C16x family has an segmented address space of up to 16MB (only 256KB on
some devices). Code segments are of 64KB size, data pages of 16KB size. Additionally, 64KB
non segmented address space is available.
The C16x family has an segmented address space of up to 16MB (only 256KB on
some devices). Code segments are of 64KB size, data pages of 16KB size. Additionally, 64KB
non segmented address space is available.
The internal address space is up to 128KB ROM/Flash-EPROM. Depending
on the derivative, there are up to 4KB RAM and 1KB SFR's present.
Memory access with PEC
The memory accesses the Peripheral Event Controller can do, are
limited to the first 64k segment. When using a derivative with internal code memory, it
seems that PEC accesses can not be made to external memory, as the first 64k are occupied
by the code memory.
However, by using the programable chip selects, accesses can be
redirected to external memory locations. When reprogramming chip selects, pay special
attention to the current code area. If the chip select currently used to fetch programm
code is reprogrammed, it needs to be ensured that the new memory area used by the
reprogrammed chip select contains valid code. In general, it is recommended to have an
exact copy of same code in both memory locations.
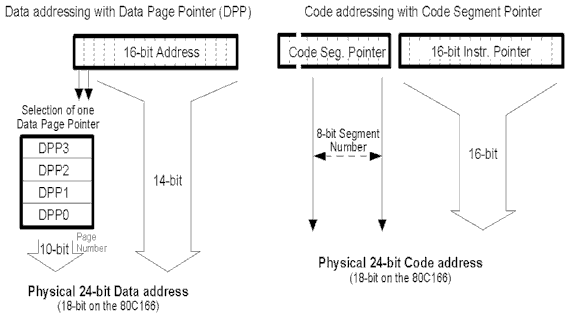
The addressing scheme below shows how the code segments and data
pages are addressed. This is done using the Code Segment Pointer (CSP) and the 4 Data Page
Pointers (DPPx).
In the C16x, branches to interrupts make use of the injected
instruction technique and thus vectoring to service routines are achieved in only min
250ns (400ns typ.). The effect of complex but necessary instructions such as MUL and DIV
(5 and 10 cycles respectively) might be expected to stretch this, but it is interesting to
note that the C16x provides these as interruptable instructions.
Very fast interrupt service is crucial in high-end applications such
as engine management systems, servo drives and radar systems where real-world timings are
used in DSP-style calculations. As these normally form part of a larger closed control
loop, erratic latency times manifest themselves as undesirable jitters in the controlled
variable.
To maximise the rate at which instructions are executed, RISC CPU's
are very heavily pipelined. On any given machine cycle, the C16x can process up to 4
instructions simultaneously by overlapping the various steps:
- FETCH:
- get the opcode from the program store
- DECODE:
- identify the opcode from a small list and fetch operands
- EXECUTE:
- perform the operation denoted by opcode and initiate write result
- WRITE-BACK:
- result is returned to the specified location
Although the instruction takes four machine cycles, it is apparently
executed in just one (2 state times). Pipelining has considerable benefits for speeding up
sequential code execution as the bus is guaranteed to be more fully utilised.
However, the fetch and decode phases can simultaneously request
access to the bus, if for example, the final phase of the current instruction is a READ.
The External Bus Controller applies a WRITE, FETCH, READ priority to prevent bus
conflicts.
Coping with MUL and DIV
Multiply and divide instructions require 5 and 10 cycles
respectively and constitute the only "complex" opcodes within the RISC. These
instructions do not finish in the mandatory four (one bus) cycles. As it is not
practicable to stop the pipeline during longer instructions, dummy instructions are
injected into the decode stage, passing through the remaining stages as simple NOP
instructions.
Branches
While in-line code poses no problems for a pipelined CPU, branches
require special steps. The problem is that by the time the branch instruction has reached
the EXECUTE stage, the next in-line opcode has already been FETCHED. Thus the instruction
immediately after the branch will be executed, followed by a jump to the target address
for the branch. This peculiarity is termed a "delayed branch" and is used as an
alternative to flushing out the pipeline completely.
The situation with a conditional branch is more complicated as the
next instruction may be totally inappropriate given the result of the conditional test.
The only solution is to either add a NOP or flush the pipeline.
The solution taken in the C16x is to, in the first case, inject a
dummy instruction into the DECODE stage while the real target address is being FETCHED.
Thus, a single extra machine cycle is required to execute the branch. For the conditional
branch, the dummy is only injected if the branch is made, and not for no-branch
situations, saving time.
Loop Control
A common situation in embedded control is searching through a table.
This involves repetitive branching to a single fixed address. Without taking special
steps, a wasted machine cycle would occur during each loop. Bearing some relationship to
disk caching techniques on PC's, a "jump cache" is provided. On the first time
through the loop, the dummy instruction is injected as before and a single machine cycle
is wasted. However, the branch target address is simultaneously stored in a cache area.
Now, on subsequent passes through the loop, the target address is extracted from the cache
and injected directly into the DECODE stage. The branch now occurs in a single machine
cycle.
Coding Around The Pipeline
With the parallel nature of the CPU, care has to taken to avoid
pipeline "mirages". Most potential problems originate from the WRITE-BACK stage
using addresses that have been changed by subsequently FETCHED instructions. Although
special hardware is provided for artificially bringing forward operand READs and WRITEs,
some pipeline effects must still be kept in mind.
As an example, the general purpose register R0 is to be loaded with
a value at the top of the stack, after the stack pointer "SP" has been moved to
a new address of 0FA40H:
SP = 0FA80H
0FA80H = 0FFH - Value at old top of stack
SP = 0FA40H
0FA40H = 011H - Value at new top of stack
MOV SP,#0FA40H ; Set stack pointer to new location
POP R0 ; Get value at top of stack into R0
Machine Cycle Number ->>
-----------------------------------------------------------------------------
0 1 2 3 4
FETCH SP=0FA80H R0=XX
Get Get POP R0
MOV SP,#0FA40
DECODE SP=0FA80 R0=XX
(and get Get address Get address
operands) of SP of R0 & value
in SP (still
at 0FA80H)
EXECUTE SP=0FA80 R0=XX
WRITE-BACK R0=0FFH R0 POPped
Put #0FA40 from address
into SP #0FA80H
As the instructions overlap, the value POPed into R0 will be
incorrect. By putting an instruction between the MOV and POP, the value of SP will be
already at the new value by the time the POP gets the value of SP. Note that as WRITE
overrules READ, the updating of SP will occur before the READing of the SP value in the
decode stage of POP R0. The overlapping of instructions produces a similar effect when
disabling interrupts:
1 BCLR IEN
2 <start of region which may not be interrupted>
3 .
4 .
5 .
As the actual updating of the IEN register does not occur until machine cycle 3, either NOPs must be inserted in cycles 2 & 3 before the critical region or the interrupt disable command must be moved back two instructions.
Today, C16x parts are available with many different clock speeds and
devices are available with or without prescaler and/or PLL, allowing maximum core speeds
of 16MHz, 20MHz, 25MHz, 33MHz, 40MHz and 50MHz. Higher speeds are under development.
The original C16x has a divide by two prescaler so that a 40MHz XTAL
or oscillator is required to yield a 20MHz CPU clock. The basic unit of time in the C166
core is a single state time, corresponding to 50ns at 20MHz. Most C16x instructions
execute in two state times, i.e. 100ns.
Some parts, usually with the 'W'-suffix, have no divide by two and
thus can use a 20MHz clock source directly. Note that these parts must be used with a
crystal as they must have a 50% duty cycle clock, which cannot be guaranteed with an
oscillator module.
If an oscillator module is used, it must have a rise and fall time
of <5ns. As with other high clock rate CPUs, 40 and 32MHz crystals must be of the
parallel resonance type. These can be tricky to find and so a cheap series resonant
crystal used with an 74HC04 inverter could be an alternative to a full oscillator module.
The C167CR and C167SR are all of the 'W' type in that they can use a
20MHz crystal. They can also use a 5Mhz crystal and use the on-chip PLL to perform a x4
frequency multiplication up to the usual 20MHz. The PLL is enabled by a pull down resistor
on P0L.
Infineon's recommended oscillator circuit for the 40 MHz version:
C2 R2 ____ C2 = 27pF +/- 20%
+--||---+-----|____|---O XTAL 2 R2 = 0..500 Ohm
| |
GND--| |XXX| Crystal (3rd Overtone)
| C1 |
+--||---+--------------O XTAL 1 C1 = 39pF +/- 20%
|
|X|
|X| L1 = 1.5 uH +/- 20%
|X|
__|__
_____ C3 = 1nF
|
GND
Note: This will work in 80% of all applications. Every design
is specific (noise, layout). An oscillator circuit research/development might be necessary
for user specific circuits.
The C16x has five bus modes:
- Single Chip Mode
- 16/18-Bit Address, 8-Bit Data, Multiplexed Bus
- 16/18-Bit Address, 8-Bit Data, Non-Multiplexed Bus
- 16/18-Bit Address, 16-Bit Data, Multiplexed Bus
- 16/18-Bit Address, 16-Bit Data, Non-Multiplexed Bus
The basic philosophy behind the bus interface is simplicity: by
providing non-multiplexed modes, it is possible to provide just a ROM and RAM to make a
working C16x system. Derivatives with integrated chip selects can make all decoder logic
redundant. Thus, despite is 20 fold improvement in performance, a C166 digital design can
be simpler than an 8031!
One of the C16x's most useful features is its ability to support two
different bus configurations in a single hardware design. Thus while the main code and
data areas can be 16 bit non-multiplexed with zero wait states for best speed, slow (and
low cost) peripherals such as RTCs can be addressed with, for example, and 8-bit bus with
3 wait states.
This secondary bus mode is controlled by the BUSCON1 and ADDRESEL1
registers which set the mode and address range base address respectively. In the C165 and
C167, a further 3 secondary bus regions can be defined, each with its own external chip
select (CS) pin for direct connection to peripheral devices' chip enable inputs.
In the following table, times are given for 20 MHz CPU clock rate. Please
note: the external bus speed is optimised by prefetching into the instruction queue!
| |
Single
Chip Mode |
16 bit Data
16/24 bit Addr
NON MUX |
16 bit Data
16/24 bit Addr
MUX |
8 bit Data
16/24 bit Addr
NON MUX |
8 bit Data
16/24 bit Addr
MUX |
| Used Ports |
none |
Port 0,1,4 |
Port 1,4 |
Port 0,1,4 |
Port 1,4 |
| Address Latch |
none |
none |
16 bit |
none |
8 bit |
Bus Cycle
Time at
0/1/2 WS |
100ns/
100ns/
100ns |
100ns/
150ns/
200ns |
150ns/
200ns/
250ns |
100ns/
150ns/
200ns |
150ns/
200ns/
250ns |
Instr. Fetch
Time 1 Word
at 0/1/2 WS |
100ns/
100ns/
100ns |
100ns/
150ns/
200ns |
150ns/
200ns/
250ns |
200ns/
300ns/
400ns |
300ns/
400ns/
500ns |
Instr Fetch
Time 2 Word
at 0/1/2 WS |
100ns/
100ns/
100ns |
200ns/
300ns/
400ns |
200ns/
300ns/
400ns |
400ns/
600ns/
800ns |
600ns/
800ns/
1us |
EPROM
Access Time
at 0/1/2 WS |
n.a. |
70ns/
120ns/
170ns |
70ns/
120ns/
170ns |
70ns/
120ns/
170ns |
70ns/
120ns/
170ns |
Relative Speed
at 0/1/2 WS |
1/
1/
1 |
1.2/
1.5/
2.0 |
1.5/
2.0/
2.5 |
2.0/
2.5/
3.0 |
3.0/
4.5/
6.0 |
(WS = Wait States)
There are many devices available and new ones are added regulary.
The following table does only contain devices which are usually available
"off-the-shelf" through distribution. We will not add new or announced devices,
until they are available in quantities, preferably through distribution.
Technology: CMOS
Ambient Temp: Ranges from 0*C to +70 *C or -40*C to +125 *C
available.
VCC: Dpending on part: 5 volts +- 10%, 3V parts available
Power: 90-180 mA,
Idle/Powerdown: 20 mA, 100 *A
| Part Number |
MHz |
RAM |
ROM |
CS |
Space |
Housing |
Peripherals |
| SABC161V-L16M |
16 |
1K |
ROMless |
0 |
4 MB |
MQFP-80-1 |
ASC, SSC |
| SABC161K-L16M |
16 |
1K |
ROMless |
2 |
4 MB |
MQFP-80-1 |
ASC, SSC |
| SABC161O-L16M |
16 |
2K |
ROMless |
4 |
4 MB |
MQFP-80-1 |
ASC, SSC |
| SABC163-L(25)F |
20/(25) |
1K |
ROMless |
4 |
16 MB |
TQFP-100 |
ASC, SSP |
| ST10F163BT1 |
25 |
1K |
128k Flash |
4 |
16 MB |
TQFP-100 |
ASC, SSP |
| SABC165-L(25)F |
20/(25) |
2K |
ROMless |
4 |
16 MB |
TQFP-100 |
ASC, SSC |
| SABC165-RM |
20 |
2K |
4K ROM |
4 |
16 MB |
MQFP-100 |
ASC, SSC |
| SABC165-L(25)M |
20/(25) |
2K |
ROMless |
4 |
16 MB |
MQFP-100 |
ASC, SSC |
| SAB80C166-M(25) |
20/(25) |
1K |
ROMless |
0 |
256 K |
MQFP-100 |
2 ASC, ADC, CAPCOM |
| SAB83C166-5M(25) |
20/(25) |
1K |
32K ROM |
0 |
256 K |
MQFP-100 |
2 ASC, ADC, CAPCOM |
| SAB88C166-5M |
20 |
1K |
32K Flash |
0 |
256 K |
MQFP-100 |
2 ASC, ADC, CAPCOM |
| SABC167-LM |
20 |
2K |
ROMless |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM |
| SABC167(S|C)R-L(25)M |
20/(25) |
4K |
ROMless |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM, C=CAN |
| SABC167S-4RM |
20 |
4K |
32K ROM |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM |
ST10R167
ST10C167-Q3 |
20 |
4K |
ROMless,
32K ROM |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM, CAN |
| SABC167CR-16RM |
20 |
4K |
128K ROM |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM, CAN |
| ST10F167-Q6 |
20 |
4K |
128K Flash |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM, CAN |
| ST10F168 |
25 |
8K |
256K Flash |
4 |
16 MB |
MQFP-144 |
ASC, SSC, ADC, PWM,
CAPCOM |
| ST10R272 |
50 |
1K |
ROMless |
4 |
16 MB |
TQFP-100 |
ASC, SSP, PWM, MAC,
CAN |
ASC = Asynchrounos Serial Interface (UART), SSP = Synchronous Serial
Port, SSC = High-Speed Synchronous Serial Interface, ADC = A/D Converter, PWM = Pulse
Width Modulation Gernerator, CAPCOM = Capture and Compare unit, CAN = Controller Area
Network Interface, MAC = DSP Multiply accumulate, I2C = I Square C unit.
Part numbers starting with SAB are from Infineon Technologies, part
numbers starting with ST are from STMicroelectronics.
For more information on the housings of these microcontrollers and
how to adapt test equipment to these, browser Hitex' adapter web page at
Block Diagramms
The best way to view block diagrams of the C16x devices is using
DAvE, Infineon's Digital Application Engineer: http://www.infineon.com/dave
Comparing microcontrollers is always difficult. Usually each chip
manufacturer has benchmarks showing that their controller is the best. The following
comparisons were published by third party support companies, which all offer products for
microcontrollers from several manufacturers...
CMX published a white paper about the context switch times of their
CMX-REAL-Time Multi-Tasking Operating System on different microcontrollers. Before reading
the results, you should take yourself the time to read the following notes:
- The "Context Switch Time" was calculated on the current
task that was running, having its context saved and the higher priority users' task
becoming the new running task.
- The scheduler is written in assembly. So the context switch times
stated are not dependant on any compiler.
- CMX tried to use "comparable" memory models on each
microcontroller. Paging was not used. No wait states were introduced.
- The C16x has 2 stack areas (SYSTEM and USER). The RTOS saves and
restores the SYSTEM stack during saving or restoring of a task. The SYSTEM stack is only
used to store the return addresses of nested functions called by a task. Depending on the
number of words used by the system stack, the context switch time may increase. Add 500
nanoseconds for each word in the stack.
And now - let's see the result:
| Microcontroller |
Internal Speed |
Context Switch Time |
Speed Factor |
| C16x |
40 MHz |
11.20 microseconds |
1 |
| 68332 |
20 MHz |
25.15 microseconds |
1.13 |
| 68HC16 |
16.78 MHz |
41.50 microseconds |
1.55 |
| 80196 |
20 MHz |
37.80 microseconds |
1.69 |
The Speed Factor is a theoretic value: if all processors would run
with the same internal speed, they would need "Speed Factor" times longer for
the context switching (compared to the C16x - "of course").
The following is a comparison of the machine cycles needed to finish
instructions on a CISC and on a RISC architecture.
CISC RISC
--------------------------------------------------------------------------
Number of
Basic Instructions 85 55
Instruction 80C196 Cycles C16x Cycles Difference
--------------------------------------------------------------------------
Move word direct LD x,y 4 MOV Rw,Rw 2 2
Move word indirect LD x,[y] 5 MOV Rw,[Rw] 2 3
Move word indexed LD x,z[y] 7 MOV Rw,[Rw+#d16] 4 3
Add words direct ADD x,y 4 ADD Rw,Rw 2 2
Add words indirect ADD x,[y] 5 ADD Rw,[Rw] 2 3
Add words indexed ADD x,x[y] 7 ADD Rw,[RW+#d16] 4 3
Multiply words direct MUL x,y 16 MUL Rw,Rw 10 6
Multiply words indirect MUL x,[y] 18 N/A
Multiply words indexed MUL x,x[y] 20 N/A
Divide words direct DIV x,y 26 DIV Rw 20 6
Divide words indirect DIV x,[y] 28 N/A
Divide words indexed DIV x,z[y] 30 N/A
16 bit uncond.jump LJMP #16 7 JMPA cc_UC,#d16 4 3
Shift Left 16 places SHL x,#16 22 SHL Rw,Rw 4(*) 18
Software interrupt TRAP 16 TRAP #n 4 12
Return from subroutine RET 11 RET 2 9
Direct data on stack PUSH x 6 PUSH Rw 2 4
Indirect data on stack PUSH [y] 9 N/A
Indexed data on stack PUSH z[y] 10 N/A
--------------------------------------------------------------------------
(*) with C16x, both operands in shift must be held in registers and
hence an additional two states area included for loading number of shifts
into a GPR, Rw.
By considering the simpler instructions which form the bulk of any
program, it can be seen that the CISC requires approximately twice the number of state
times of the RISC. For instructions that change program flow, the CISC overhead is even
greater at a factor of 4. Taken over a complete software system, the RISC advantage should
be a reduction in run times by about 50%.
If YOU know anything to add here, please send us an email: FAQ@ESAcademy.com
If you have a question concerning the C16x / ST10 which are NOT
answered by this FAQ, you may want to send it to one of the following email addresses:
We know of none C16x related mailing list so far - please let us
know if you do!
For CAN related topics, there is a mailing list. The archive is at http://www.scruz.net/~cichlid/can-archive.
To subscribe to the list, send an email to can-request@cichlid.com with the subject "SUBSCRIBE your@email.address".
There are almost no free or public domain tools available. However,
most tool manufacturers offer powerfull evaluation version of their software. These are
usally full blown versions with just one restriction: the total code size they can
produce/handle is limited. Depending on the manufacturer this can be somewhere between 4k
to 8k of code.
DAvE
One of the best tools available is DAvE - and he is free. DAvE is
Siemens' Digital Application Engineer and comes on a CD-ROM. DAvE offers a setup wizard
helping you to configure all the peripherals.
A short example: to configure the serial port, simply specify the
needed baud rate and select the functions (like interrupt service routines for transmit,
receive and errors) DAvE should create. Click on the "generate code" button and
DAvE generates the C source code - compilable with Keil or Tasking. For more information
on DAvE browse: http://www.infineon.com/dave.
Free Assemblers
A free MAcro Assembler supporting many embedded microcontrollers
including the 80C16x and ST10 family is available at: http://john.ccac.rwth-aachen.de:8000/as/
Free C compilers
Both Keil and Tasking offer powerfull evaluation versions of their
commercial compilers. Check them out at http://www.keil.com
and http://www.tasking.com.
Currently (as of Fall 1999), Hitex Development Tools USA has a
special offer for North American customers. The compiler is included for free with the
purchase of their DProbe167 system. For details, see: http://www.hitex.com/hitools/deal.htm.
There are many sources for commercially available products on the
web.
Start by browsing the SPACE tools web page at http://www.spacetools.com.
Siemens has all Data books and Application notes available on the
DAvE CD-ROM. Including context sensitive and smart search options: http://www.infineon.com/dave.
STMicroelectronics offers their manuals in .PDF files. The data
books are available from their web page http://www.st.com/stonline/books/index.htm.
In addition, Hitex UK offers "The Insider's
Guide To Planning C166 Family Designs". This guide offers
many additional tips and techniques about the hardware and software design. You can find
the on-line version at: http://www.hitex.co.uk/book166/166des19-a.html.
Disclaimer:
Copyright (c) 1999, 2000 by Embedded Systems Academy (www.ESAcademy.com), all rights reserved.
This FAQ may not be included in commercial collections or
compilations without express permission from the Embedded Systems Academy.
The information presented was collected from various sources and is
presented "as is". The authors and the Embedded Systems Academy are not
responsible for the accuracy of the contents.